Rotation Invariant Convolutions for 3D Point Clouds Analysis

3D point clouds deep learning is a promising field of research that allows a neural network to learn features of point clouds directly, making it a robust tool for solving 3D scene understanding tasks. While recent works show that point cloud convolutions can be invariant to translation and point permutation, investigations of the rotation invariance property for point cloud convolution has been so far scarce. Some existing methods perform point cloud convolutions with rotation-invariant features, existing methods generally do not perform as well as translation-invariant only counterpart. In this work, we argue that a key reason is that compared to point coordinates, rotation-invariant features consumed by point cloud convolution are not as distinctive. To address this problem, we propose a simple yet effective convolution operator that enhances feature distinction by designing powerful rotation invariant features from the local regions. We consider the relationship between the point of interest and its neighbors as well as the internal relationship of the neighbors to largely improve the feature descriptiveness. Our network architecture can capture both local and global context by simply tuning the neighborhood size in each convolution layer. We conduct experiments on synthetic and real-world point cloud classifications, part segmentation, and shape retrieval to evaluate our method, which achieves the state-of-the-art accuracy under challenging rotations.
Materials
 Paper [IJCV2022] |
 Paper [3DV2020] |
 Paper [3DV2019] |
Code on GitHub [IJCV2022] |
Code on Gitee [IJCV2022] |
Code on GitHub [3DV2019] |
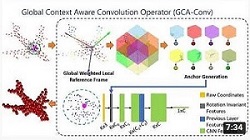 Video [3DV2020] |
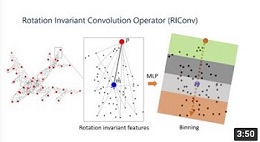 Video [3DV2019] |
 Poster [3DV2019] |
Citations
If you find this work useful, please cite the following papers.
@article{zhang2022riconv2,
title={RIConv++: Effective Rotation Invariant Convolutions for 3D Point Clouds Deep Learning},
author={Zhang, Zhiyuan and Hua, Binh-Son and Yeung, Sai-Kit},
journal={International Journal of Computer Vision},
volume={1},
pages={1--16},
year={2022}
}
@inproceedings{zhang2020global,
title={Global Context Aware Convolutions for 3D Point Cloud Understanding},
author={Zhang, Zhiyuan and Hua, Binh-Son and Chen, Wei and Tian, Yibin and Yeung, Sai-Kit},
booktitle={2020 International Conference on 3D Vision (3DV)},
pages={210--219},
year={2020}
}
@inproceedings{zhang2019rotation,
title={Rotation Invariant Convolutions for 3D Point Clouds Deep Learning},
author={Zhang, Zhiyuan and Hua, Binh-Son and Rosen, David W and Yeung, Sai-Kit},
booktitle={2019 International Conference on 3D Vision (3DV)},
pages={204--213},
year={2019}
}
Acknowledgements
The authors acknowledge the grant from Ningbo Research Institute of Zhejiang University (1149957B20210125), and the support from the SUTD Digital Manufacturing and Design Centre (DManD) funded by the Singapore National Research Foundation. This project is also partially supported by Singapore MOE Academic Research Fund MOE2016-T2-2-154 and Singapore NRF under its Virtual Singapore Award No. NRF2015VSGAA3DCM001-014, and an internal grant from HKUST (R9429).